
今天要談論的問題是今天若是我們訓練好一個TensorFlow的模型要怎麼放置雲端平台,可能給別人使用或是為自己的實驗做串接,一樣先創建notebooks接著切換至training-data-analyst > courses > machine_learning > deepdive > 03_tensorflow > labs 打開 e_ai_platform.ipynb,開始進行實驗。
import os
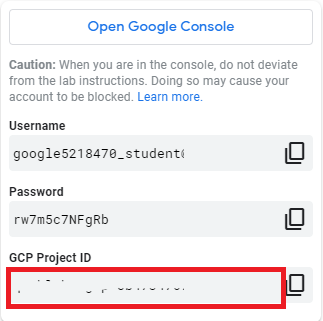
PROJECT = 'xxx' # 改成自己的 PROJECT ID
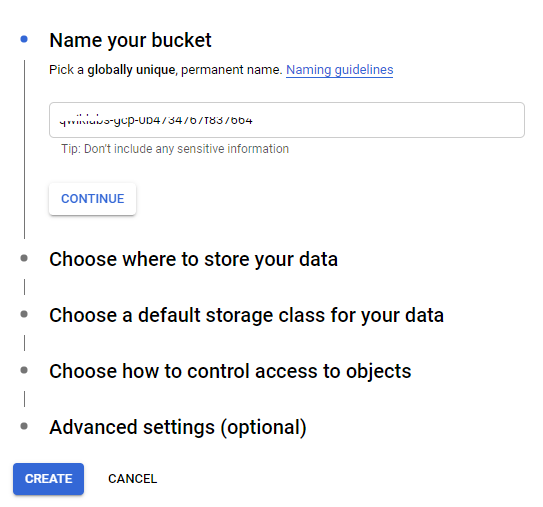
BUCKET = 'xxx' # 改成自己的 BUCKET NAME
REGION = 'xxx' # 改成自己的 BUCKET REGION e.g. us-central1
MODEL_NAME = 'taxifare' #model名字
MODEL_VERSION = 'v1' #model版本
TRAINING_DIR = 'taxi_trained' #訓練時存放資料的資料夾
os.environ['PROJECT'] = PROJECT
os.environ['BUCKET'] = BUCKET
os.environ['REGION'] = REGION
os.environ['MODEL_NAME'] = MODEL_NAME
os.environ['MODEL_VERSION'] = MODEL_VERSION
os.environ['TRAINING_DIR'] = TRAINING_DIR
os.environ['TFVERSION'] = '1.14' # Tensorflow 版本
gcloud config set 的指令來設置此次所需的專案、進行計算的區域,並且將其專案與bucket進行連結。%%bash
gcloud config set project $PROJECT #設置專案
gcloud config set compute/region $REGION #設置實行計算地點
get的方式來進行帳戶連結echo的內容%%bash
echo "Getting the service account email associated with the Cloud AI Platform API"
AUTH_TOKEN=$(gcloud auth print-access-token)
SVC_ACCOUNT=$(curl -X GET -H "Content-Type: application/json" \
-H "Authorization: Bearer $AUTH_TOKEN" \
https://ml.googleapis.com/v1/projects/${PROJECT}:getConfig \
| python -c "import json; import sys; response = json.load(sys.stdin); \
print (response['serviceAccount'])")
#如果這邊有問題代表Cloud Machine Learning Engine API沒有被enable,要檢查一下API是否有啟動
echo "Authorizing the Cloud AI Platform account $SVC_ACCOUNT to access files in $BUCKET"
gsutil -m defacl ch -u $SVC_ACCOUNT:R gs://$BUCKET
gsutil -m acl ch -u $SVC_ACCOUNT:R -r gs://$BUCKET
gsutil -m acl ch -u $SVC_ACCOUNT:W gs://$BUCKET
#這邊要確定的是BUCKET是不是確實有被建立

cat來複製到雲端來做使用head來查看檔案是否正確rm -rf的語法強制刪除所有檔案%%bash
find ${MODEL_NAME}

%%bash
cat ${MODEL_NAME}/trainer/model.py
%%bash
echo "Working Directory: ${PWD}" #印出現在路徑
echo "Head of [train_file].csv"
head -1 $PWD/[train_file].csv #查看路徑下訓練檔案中第一筆
echo "Head of [valid_file].csv"
head -1 $PWD/[valid_file].csv #查看路徑下驗證檔案第一筆

python -m的是以腳本方式做啟動,並規範訓練、驗證、輸出資料後決定訓練長度開始訓練writefile,寫入當前目錄%%bash
export PYTHONPATH=${PYTHONPATH}:${PWD}/${MODEL_NAME}
python -m trainer.task \ #呼叫trainer內的task檔輸入參數
--train_data_paths="${PWD}/[train_file]*" \ #訓練路徑
--eval_data_paths=${PWD}/[valid_file].csv \ #驗證路徑
--output_dir=${PWD}/${TRAINING_DIR} \ #輸出路徑
--train_steps=1000 #訓練需要幾個步驟
--job-dir=./tmp #此項任務放置於那裡

%%writefile ./[json_file_name].json #寫入自製json檔
{"pickuplon": xxx,"pickuplat": xxx,"dropofflon": xxx,"dropofflat": xxx,"passengers": x}

%%bash
model_dir=$(ls ${PWD}/${模型位置} | tail -1) #設定模型位置下的第一筆資料
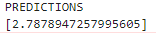
gcloud ai-platform local predict \ #連結到gcloud中進行預測
--model-dir=${PWD}/${模型位置}${model_dir} \ #讀取模型
--json-instances=./[json_file_name].json #放置想要預測的檔案
%%bash rm -rf $PWD/${TRAINING_DIR}
%%bash
gcloud ai-platform local train \ # 接到gcloud訓練
--module-name=trainer.task \ #要用到的是甚麼模組
--package-path=${PWD}/${套件位置} \ #相關套件位置
-- \
--train_data_paths=${PWD}/[train_file].csv \ #訓練路徑
--eval_data_paths=${PWD}/[valid_file].csv \ #驗證路徑
--train_steps=1000 \ #訓練需要幾個步驟
--output_dir=${PWD}/${TRAINING_DIR} #輸出資料夾
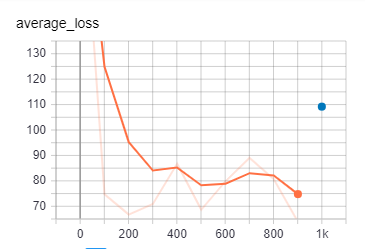
%%bash
ls $PWD/${TRAINING_DIR}
%%bash
echo $BUCKET
gsutil -m rm -rf gs://${BUCKET}/{BUCKET位置}/ #移除原本在BUCKET的檔案
gsutil -m cp ${PWD}/*.csv gs://${BUCKET}/{BUCKET位置}/ #將現在位子的檔案移動至BUCKET

%%bash
OUTDIR=gs://${BUCKET}/{BUCKET輸出位置} #設置BUCKET輸出位置
JOBNAME=${MODEL_NAME}_$(date -u +%y%m%d_%H%M%S) #定義此項工作名字
echo $OUTDIR $REGION $JOBNAME #查看此項工作狀態
gsutil -m rm -rf $OUTDIR #若資料夾存在則先清除資料夾
gcloud ai-platform jobs submit training $JOBNAME \ #設定此項工作參數
--region=$REGION \ #計算伺服器區域
--module-name=trainer.task \ #要使用何種模組
--package-path=${PWD}/${套件位置}\ #相關套件位置
--job-dir=$OUTDIR \ #工作輸出位置
--staging-bucket=gs://$BUCKET \ #BUCKET位置
--scale-tier=BASIC \ #scale的程度
--runtime-version=$TFVERSION \ #定義版本
-- \
--train_data_paths="gs://${BUCKET}/{訓練資料路徑}/[train_file]*" \ #輸入訓練資料集路徑
--eval_data_paths="gs://${BUCKET}/{驗證資料路徑}/[valid_file]*" \ #輸入驗證資料集路徑
--output_dir=$OUTDIR \ #輸出資料夾
--train_steps=10000 #訓練需要幾個步驟


%%bash
gsutil ls gs://${BUCKET}/{輸出檔案路徑} #檢查路徑

%%bash
MODEL_LOCATION=$(gsutil ls gs://${BUCKET}/{輸出檔案路徑} | tail -1)
echo "MODEL_LOCATION = ${MODEL_LOCATION}"
gcloud ai-platform versions delete ${MODEL_VERSION} --model ${MODEL_NAME} #刪除模型版本與名字

%%bash
MODEL_LOCATION=$(gsutil ls gs://${BUCKET}/{輸出檔案路徑} | tail -1)
echo "MODEL_LOCATION = ${MODEL_LOCATION}"
gcloud ai-platform versions create ${MODEL_VERSION} --model ${MODEL_NAME} --origin ${MODEL_LOCATION} --runtime-version $TFVERSION #創建模型名字與版本等資訊

gcloud ai-platform predict輸入訓練的模型與版本並使用剛剛創建的test.json進行預測%%bash
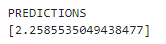
gcloud ai-platform predict --model=${MODEL_NAME} --version=${MODEL_VERSION} --json-instances=./[json_file_name].json #利用gcloud ai平台進行預測,輸入相關資訊進行預測
from googleapiclient import discovery
from oauth2client.client import GoogleCredentials
import json
credentials = GoogleCredentials.get_application_default()
api = discovery.build('ml', 'v1', credentials=credentials,
discoveryServiceUrl='https://storage.googleapis.com/cloud-ml/discovery/ml_v1_discovery.json') #json API
request_data = {'instances': #自定義json架構
[
{
'pickuplon': xxx,
'pickuplat': xxx,
'dropofflon': xxx,
'dropofflat': xxx,
'passengers': x,
}
]
}
parent = 'projects/%s/models/%s/versions/%s' % (PROJECT, MODEL_NAME, MODEL_VERSION)
#在網頁上接收data進行預測
response = api.projects().predict(body=request_data, name=parent).execute()
print ("response={0}".format(response))
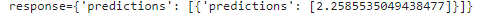
%%bash
#方法跟上面一樣,將以上兩個位置做更改,並且提高訓練步驟
--train_data_paths="gs://${CRS_BUCKET}/${MODEL_NAME}/ch3/train.csv" \
--eval_data_paths="gs://${CRS_BUCKET}/${MODEL_NAME}/ch3/valid.csv" \
--train_steps=100000 #訓練需要幾個步驟

 iThome鐵人賽
iThome鐵人賽